
Best-Practices & Challenges in LLM evaluations
A small concise list of standards in LLM Eval - Part 2 of LLM Eval Series

Evaluating LLMs can be quite hard and error prone. This comes down to the nature of the problem at hand. Often times developing a strong foundation for evaluation is quite important. Using techniques like Retrieval Augmented Generation, evaluating the response fine-tuned models by comparing them to accurate datasets is a necessity in ensuring a quality offering.
Best Practices
Some standards to follow to make sure we don’t end up in a conundrum include:
1). Benchmark, benchmark and then some more
Benchmarking or comparing our fine-tuned model’s performance to the existing industry standards is quite necessary in this day and age. Often-times this can serve as an easy win and provides stakeholders the preliminary confidence to onboard. Performance is a key objective that helps companies stay ahead in the Generative AI market.
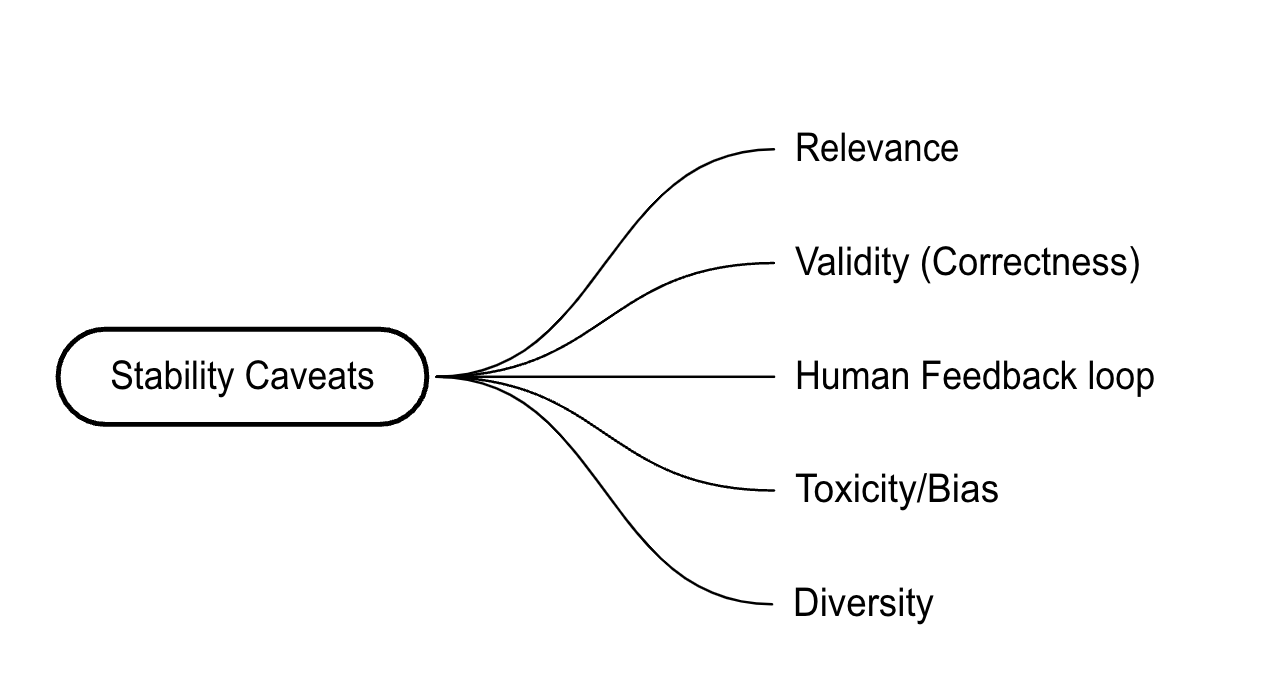
2). Stability in metrics definition
Metrics by themselves provide a quantitative/qualitative measure of how well the model responds/predicts text. Companies use a wide variety of metrics in text generation to find the perfect match. Matches consider not just exact ones but also synonyms and paraphrases. This aims to align well with multiple search mediums.
It is also important for the metric definition to be agreed upon by all the stakeholders involved in the model’s evaluation outcome. This helps ensure that the responses match the real world needs.
A quick way to visualize this:
3). Monitor, Integrate and Deploy…again and again…
It is essential to monitor for issues/errors during process, update the evaluation methodologies and integrate your findings through a continuous cycle/pipeline. This not only ensures a quality deliverable, but also helps you acclimate the myriad of ways in which real-world interactions occur.
4). Choosing the right human feedback loop..
This is as important as setting good metrics. Picking validators that have a core understanding of the space in which your LLM operates is tantamount to your offering succeeding. This is deeply nuanced and the model output effectiveness is dependent on having this set for you.
Often-times having the right expertise helps you cater to the multiple use-cases and corner cases that you might encounter in your journey to provide quality domain-tuned LLMs.
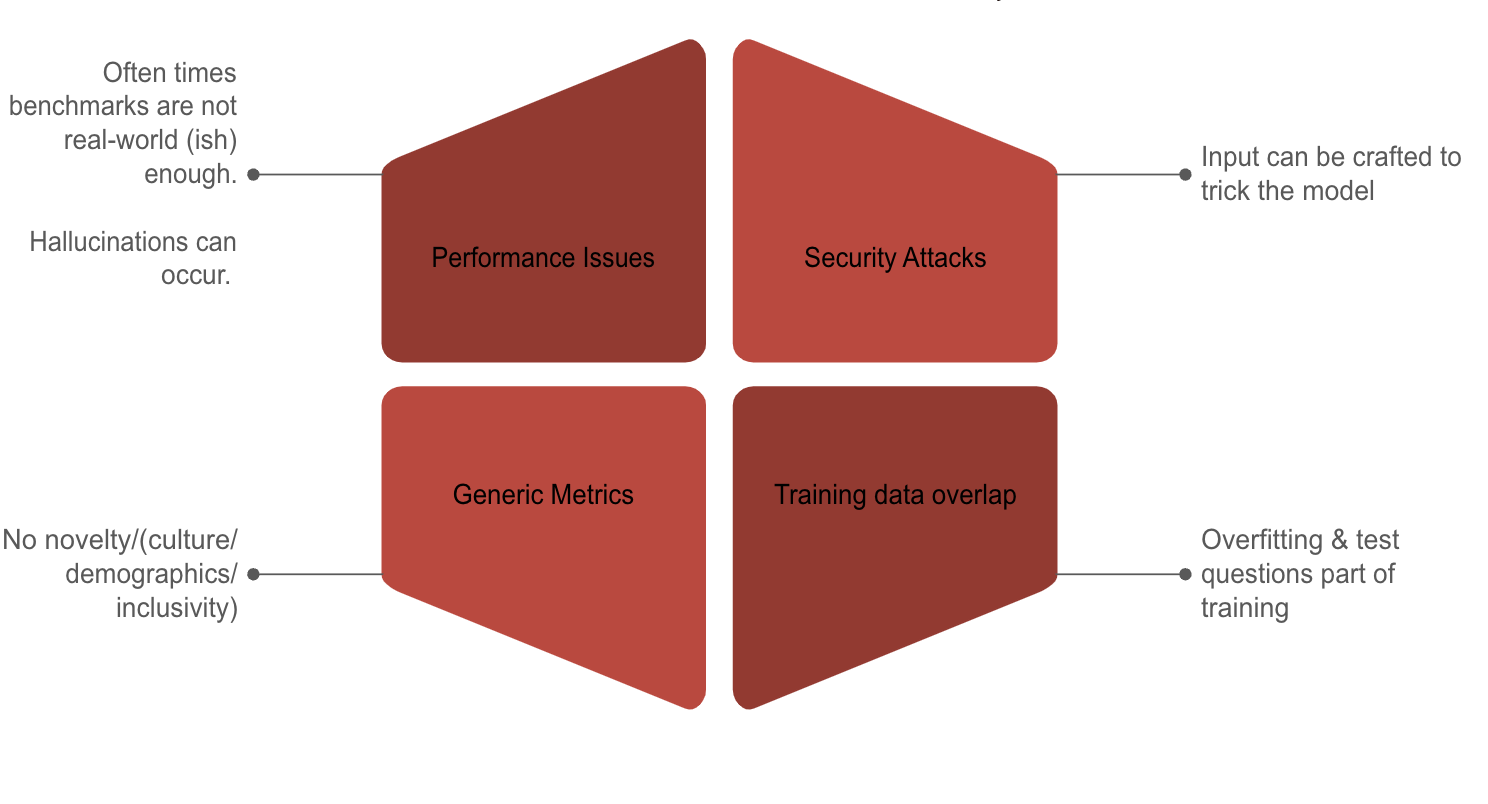
Challenges in evaluation, say what???
As with any scalable, industry ready solution, developing an operational LLM Evaluation framework can have its own set of challenges.
A brief mix of challenges below:
Some other subtle ways to achieve a modicum of success in our efforts include:
Certain times responses are too human like and this makes it harder for the model to differentiate and measure. In such cases, the scoring mechanism needs to be more dynamic and adapt to changes.
Automatic evaluations have their blind spots and being aware of that and bringing in human judgement early in the cycle helps us scale better. This is a double edged sword, as human judgements can be erroneous too with biases. It is a fine line between inconsistency and bias.
Understanding sentiments/emotions as part of the response cycle is something LLMs are just learning and we have a long way to go to achieve perfection (this might never happen as well!!). This is an area of interest for many researchers and developing for this can win many battles.
Hope you all enjoyed the second in series of this LLM Eval post. More to come and stay tuned!!